Центры обработки данных (ЦОД) — это сердце всемирной паутины, где происходит обмен и обработка огромных объёмов данных. Пакеты данных передаются по кратчайшим путям, что позволяет оптимально использовать сетевые ресурсы. В отличие от традиционных иерархических сетей, инфраструктуры дата-центров являются многоранговой плоской архитектурой. Они имеют тысячи взаимосвязанных узлов, что предъявляет высокие требования к выполнению алгоритмов поиска кратчайшего пути, от точки входящего запроса к нужному узлу (серверу). Эти сети могут состоять из десятков или сотен тысяч узлов и, естественно, страдают от частых сбоев программного (либо аппаратного) обеспечения, а также перегрузки каналов. Пакеты передаваемых данных маршрутизируются по кратчайшим путям с использованием достаточных ресурсов, чтобы обеспечить эффективное использование сети и минимизировать задержки.

В таких динамических сетях каналы связи часто выходят из строя или перегружены, что делает пересчёт кратчайшего маршрута сложной вычислительной задачей. Для решения этой проблемы были предложены различные протоколы маршрутизации, ориентированные на оптимизацию использования сети, а не на скорость. Удивительно, но разработка быстрых алгоритмов поиска кратчайшего пути для дата-центров, пока, в значительной степени, игнорировалась, хотя этот процесс является универсальным компонентом протоколов маршрутизации. Более того, методы распараллеливания, в основном, применялись для случайных топологий сети, а не для регулярных, которые часто встречаются в ЦОД.
Обладая превосходной производительностью и низким уровнем сложности алгоритмы прокладывания кратчайшего пути стали доминировать во всех типах сетей связи. Используя такие алгоритмы для маршрутизации пакетов, эти топологии максимизируют пропускную способность и минимизируют задержки. По этой причине, в протоколах маршрутизации Интернета, на протяжении десятилетий использовались такие алгоритмы, как протокол открытого кратчайшего пути (open shortest path first), протокол промежуточных систем (IS — intermediate system) и протокол пограничного шлюза (border gateway). Все они также работают в сочетании с балансировкой нагрузки. Самым популярным примером протоколов маршрутизации, используемых в центрах обработки данных, является стратегия многопутевого доступа с равной ценностью (ECMP — equal cost multipath protocol). Однако в сетях, с огромным количеством выделенных и виртуальных серверов, даже расчёт кратчайших путей представляет собой проблему из-за чрезвычайно большого количества узлов. В предыдущее время эта проблема решалась с помощью более простых алгоритмов, с меньшей производительностью. Но с ростом распространения Интернета стали использоваться новые подходы и технологические возможности для ускорения расчёта кратчайшего пути в сетях крупных дата-центров.
Теоретически, маршрутизацию в этих сетях можно упростить, используя заранее определённые таблицы поиска, основанные на их обычной (регулярной) топологии. Однако экспериментальный анализ показывает, что они часто страдают от сбоев узлов и перегрузки каналов. В случае таких событий кратчайшие пути должны быть быстро пересчитаны для изменённой топологии, которая больше не является регулярной. Однако локальная перемаршрутизация не особенно эффективна, поскольку количество альтернативных путей уменьшается по мере приближения пакетов к местам назначения. Быстрое локальное изменение маршрутизации приводит к не вполне оптимальному использованию сети и потенциальной нестабильности всего маршрута. Когда потоки трафика локально перенаправляются вокруг перегруженных каналов, это может привести к перегрузке соседних каналов и вызвать колебания в расчётах других маршрутов. Замена сегментов пути приводит к менее эффективному использованию, по сравнению с маршрутизацией по кратчайшим путям от источников к адресатам.
Балансировка нагрузки часто используется для маршрутизации пакетов информации, поскольку она способствует равномерному распределению каналов и буферов коммутатора в обычных топологиях. ECMP, который балансирует потоки по путям с равными затратами, является достаточно популярным протоколом. Однако информационные потоки могут иметь разные размеры, что может привести к неравномерному использованию каналов. Как вариант решения неравномерного распределения, было предложено централизованно планировать большие потоки, что более оптимально и менее масштабируемо, например, по протоколу F10 (tFault-Tolerant Engineered Network), который может практически мгновенно восстанавливать подключение и баланс нагрузки даже при наличии множественных сбоев. После сбоев сетевого канала и коммутатора в F10 происходит менее 1/7 потери пакетов, по сравнению с традиционными схемами топологии. А оценка производительности MapReduce, на основе трассировки, показывает, что меньшая потеря пакетов в F10 обеспечивает среднее ускорение на уровне приложения в 30%.
Другие решения включают реактивные схемы, использующие ограниченную информацию о состоянии сети. Например, в протоколе FlowBender источник отслеживает перегрузку потока с помощью явных уведомлений о перегрузке, и, при необходимости, перенаправляет поток на случайно выбранный путь ECMP. Похожая идея применяется в CONGA, где коммутатор назначения отправляет обратную связь коммутатору источника в соответствии с качеством обслуживания, измеренным на указанном пути. В виду того, что CONGA использует сложные механизмы обнаружения перегрузок, для этого требуется модификация коммутаторов.
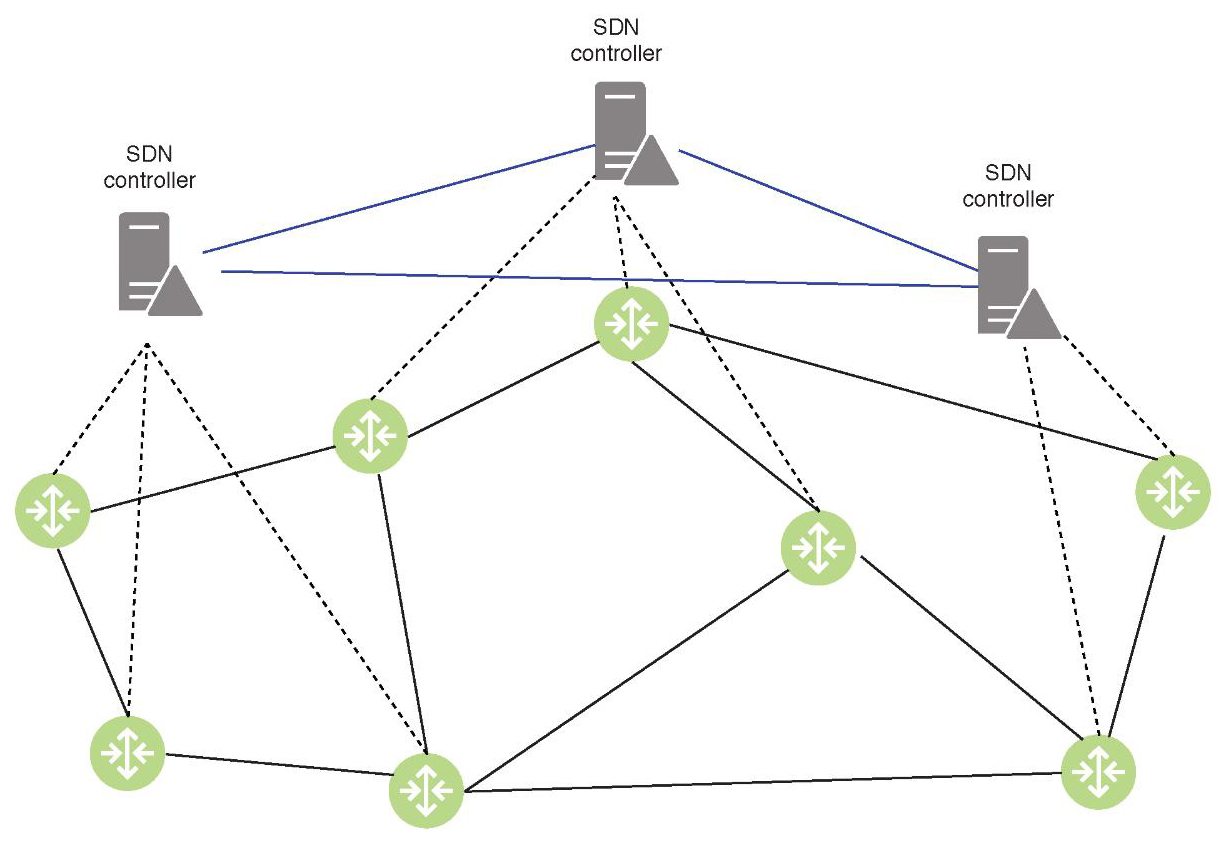
Известно, что двухфазные схемы балансировки нагрузки значительно уменьшают перегрузку в центрах обработки данных. В этих схемах пакеты маршрутизируются через узлы сети, пропорционально коэффициентам, связанным с этими узлами. Коэффициенты балансировки оптимизированы таким образом, чтобы минимизировать перегрузку сети. И ECMP, и протоколы двухфазной балансировки включают расчёт кратчайших путей. ECMP вычисляет несколько кратчайших путей между узлами, в то время как протоколы двухфазной балансировки используют кратчайшие пути для передачи пакетов к промежуточным узлам и от них. Плоскости управления коммерческих маршрутизаторов, реализующих традиционные протоколы, представляют собой закрытые решения, что делает интеграцию и управление сетевыми устройствами в огромных дата-центрах сложной задачей. Спецификации OpenFlow определяют интерфейсы между уровнями управления и передачи данных, тем самым позволяя сетевым операторам разрабатывать свои собственные алгоритмы. Плоскость управления может быть реализована контроллерами SDN, которые находятся отдельно от коммутационных устройств.
Протоколы распределённой маршрутизации более подходят для центров обработки данных, поскольку они масштабируемы и быстро реагируют на сбои, тогда как централизованный контроллер SDN ограничивает размер и надёжность. Централизованный контроллер не может вычислять и отправлять справочные таблицы всем коммутаторам в огромной сети дата-центра, одновременно быстро реагируя на изменения топологии.
Напротив, протоколы маршрутизации, выполняемые коммутационными узлами, естественным образом распараллеливают эти задачи и поддерживают гораздо более крупные сети. Гибкость, обеспечиваемая централизованным контроллером SDN, может быть легко импортирована в протоколы распределённой маршрутизации с помощью техники выдуманной подстановки, которой сразу дали название Фиббинг (Fibbing). В сущности — это архитектура, которая обеспечивает гибкость и надёжность за счёт централизованного управления распределённой маршрутизацией. Суть процедуры в том, что система вводит поддельные узлы и ссылки в базовый протокол маршрутизации по состоянию канала, таким образом, что маршрутизаторы вычисляют свои собственные таблицы пересылки, на основе расширенной топологии. Распределение является выразительным и легко поддерживает гибкую балансировку нагрузки, управление трафиком и резервные маршруты. Основываясь на требованиях к переадресации высокого уровня, контроллер вычисляет компактную расширенную топологию и вводит поддельные компоненты с помощью стандартных сообщений протокола маршрутизации. Он работает с любыми немодифицированными маршрутизаторами, поддерживающими OSPF и может масштабироваться до крупных сетей с множеством требований к пересылке, обеспечивает минимальные накладные расходы и быстро реагирует на сбои сети и контроллера.
Пути резервного копирования, балансировка нагрузки и перенаправление потоков через промежуточные узлы могут быть реализованы с использованием поддельных узлов. Техника выдумки основана на распределённых алгоритмах поиска кратчайшего пути, которые должны выполняться всякий раз, когда топология сети изменяется при добавлении поддельных узлов для предоставления новых функций. Для коммутационных узлов пути маршрутизации должны пересчитываться быстрее, чем это возможно централизованным контроллером SDN, обеспечивая при этом тот же уровень программируемости.
Эти алгоритмы поиска кратчайшего пути распределяются по узлам коммутации и дополнительно распараллеливаются на этих узлах. Протоколы распределённой маршрутизации могут быть реализованы разными способами. Например, коммутаторы Top-of-Rack (TOR) могут использовать усовершенствованные центральные процессоры и реализовывать собственные плоскости управления, подобно обычным маршрутизаторам. Другой вариант — назначить в каждой стойке по одному серверу для расчёта справочных таблиц маршрутизации для программируемых коммутаторов TOR. Наконец, серверы, на которых размещено большое количество карт PCIe, могут функционировать как маршрутизаторы TOR высокой производительности. Сервер может реализовать программный маршрутизатор с плоскостью управления и плоскостью быстрой передачи данных, используя различные высокоскоростные платформы. Быстрая плоскость данных на основе платформы DPDK (Data Plane Development Kit) обеспечивает наилучшую производительность. Пропускная способность серверов может быть дополнительно увеличена, посредством передачи обработки пакетов на микросхемы FPGA (Field-Programmable Gate Array).
Как показывает практика, алгоритмы поиска кратчайшего пути можно реализовать значительно быстрее на экономичных процессорах общего назначения, используя методы распараллеливания. Сокращение времени вычислений лучшего маршрута, с помощью распараллеливания между несколькими ядрами, позволяет более гибко адаптироваться к изменениям топологии в сетях крупных ЦОД, а также более эффективно распределять сетевые ресурсы, в соответствии с изменениями в структуре трафика.




